Improve Incident and Problem Management
Rise above firefighter mode with structured incident management to enable effective problem management.
- IT infrastructure managers have conflicting accountabilities. It can be difficult to fight fires as they appear while engaging in systematic fire prevention.
- Repetitive interruptions erode faith in IT. If incidents recur consistently, why should the business trust IT to resolve them?
Our Advice
Critical Insight
- Don’t risk muddling the chain of command during a crisis. Streamline the process. When senior technical staff are working on incidents, they report to the service desk manager.
- Incidents defy planning, but problem management is schedulable. Schedule problem management; reduce unplanned work.
- Just because a problem has not caused an incident doesn’t mean it never will. Get out in front of problems. Maximize uptime.
Impact and Result
- Define the roles and responsibilities of the incident manager and the problem manager.
- Develop a critical incident management workflow that will save money by streamlining escalation.
- Create a problem management standard operating procedure that will reduce incident volume, save money, and allow upper tier support staff to engage in planned work as opposed to firefighting.
Member Testimonials
After each Info-Tech experience, we ask our members to quantify the real-time savings, monetary impact, and project improvements our research helped them achieve. See our top member experiences for this blueprint and what our clients have to say.
8.8/10
Overall Impact
$66,844
Average $ Saved
26
Average Days Saved
Client
Experience
Impact
$ Saved
Days Saved
Institute for Health Metrics and Evaluation - University of Washington
Guided Implementation
9/10
$10,880
6
State of Ohio - Ohio Department of Developmental Disabilities
Guided Implementation
4/10
N/A
N/A
Ben is very knowledgeable. The topic was just not what we were looking for right now. Thank you Ben!
Omaha Public Power District
Guided Implementation
10/10
N/A
1
We're still gathering a data set to determine this information as to impact and cost. However, the ability to validate our framework, methodology, ... Read More
AgWest Farm Credit, FLCA
Guided Implementation
8/10
N/A
10
Frank's insight is always valuable in our project. Once again he offered validation and confidence in the project we were working on.
Florida Department of Revenue
Guided Implementation
10/10
N/A
55
Best - very friendly, knowledgeable, and ready to help. Worst - N/A.
Sunrun South LLC
Guided Implementation
10/10
$136K
44
WA Department of Transport
Guided Implementation
10/10
N/A
N/A
It is too early on to estimate time and $ savings however the advice is definitely assisting with breaking through long established practices that ... Read More
Brockville General Hospital
Guided Implementation
10/10
$35,000
20
The standardized approach with the ability to tailor the outcomes to the local organization was really appreciated. The support from Ben was fabul... Read More
WA Department of Transport
Guided Implementation
9/10
N/A
N/A
Assistance in relating process to required capabilities and competencies. The valued role of a referential third part in overcoming opposing positi... Read More
Vitech Systems Sub LLC (d/b/a Vitech Systems Group)
Guided Implementation
2/10
N/A
N/A
there isn't a best. The analyst "disappeared" (not further contact) after 3 or 4 calls and did not respond after that.
Vancouver Island University
Guided Implementation
10/10
$2,000
5
Ben was super helpful, made many practical suggestions, and was very valuable in helping us to tailor the templates to meet our specific needs. Th... Read More
Hydro Tasmania
Guided Implementation
9/10
N/A
5
Loomis AB
Guided Implementation
10/10
$73,999
5
the informtation was informative and easy to understand and more on the site for me to look at. If i also have any questions Frank is available for... Read More
New York Property Insurance Underwriting Association
Workshop
10/10
N/A
N/A
The sessions were very informative, and material provided will help us improve our processes further. We've not done any RoI so I wont be able to p... Read More
Pioneer Natural Resources
Workshop
10/10
$274K
120
The workshop was exceptional. Jeremy is extremely knowledgeable. He gives relatable examples, talks specifics where applicable, and keeps things mo... Read More
Highlands County Clerk of Courts
Guided Implementation
10/10
$2,740
20
Geidea
Guided Implementation
9/10
N/A
N/A
clear explanations from Franck for Problem Management and outcome of calls very interesting, thanks. We will certainly contact Franck for Crisis Ma... Read More
State of Ohio - Ohio Bureau of Workers' Compensation
Workshop
9/10
N/A
N/A
The best and the worst are the same. We were given a great deal of knowledge in these sessions. That is very good. Finding the time to make the cha... Read More
SCEE
Guided Implementation
10/10
$1,820
10
Nieuport Aviation
Guided Implementation
9/10
$6,000
14
Guided Implementation
9/10
$64,999
10
Best: Validated our approach and our current path. Analyst was very knowledgable. Worse: Was about structure - yes, the uber topic is Inciden... Read More
Mount Royal University
Guided Implementation
10/10
N/A
N/A
It was a pleasure to meet with Sandi. She took the time to understand my needs and then directed me to the best resource and materials. San... Read More
Virginia Community College System
Workshop
10/10
N/A
20
The best part of the workshop was how the leaders skillfully walked us through the material and lead us towards a better understanding of how our o... Read More
General Conference of Seventh-day Adventists
Workshop
9/10
$27,880
20
The communication that the workshop engendered within our team was helpful. We had worked a lot out prior to the workshop but this helped us to ref... Read More
Oregon Secretary of State
Guided Implementation
10/10
$2,519
N/A
Akin Gump Strauss Hauer & Feld LLP
Workshop
9/10
$34,000
5
The University of Texas at San Antonio
Guided Implementation
8/10
$74,800
120
World Bank Group
Guided Implementation
10/10
$2,720
5
I really appreciated the follow-up notes after each meeting. Especially additional resources to review and get more information from. I also enjoye... Read More
Alexion Pharma LLC
Guided Implementation
10/10
$100K
20
The presentation was concise and well presented. The presentation gave me food for thought as to how to rethink problem management. Thank you.
Mott MacDonald LLC
Guided Implementation
10/10
$46,249
9

Incident and Problem Management
Resolve service issues faster and eliminate recurring incidents.
This course makes up part of the Infrastructure & Operations Certificate.
- Course Modules: 4
- Estimated Completion Time: 2-2.5 hours
Workshop: Improve Incident and Problem Management
Workshops offer an easy way to accelerate your project. If you are unable to do the project yourself, and a Guided Implementation isn't enough, we offer low-cost delivery of our project workshops. We take you through every phase of your project and ensure that you have a roadmap in place to complete your project successfully.
Module 1: Incident ticket intake and routing
The Purpose
- Improve how tickets logged, categorized, and prioritized.
Key Benefits Achieved
- Efficient ticket processing and consistent treatment of tickets based on severity.
Activities
Outputs
Review incident lifecycle and current challenges.
Roles and responsibilities for service desk.
Review ticket categorization.
Prioritization schema.
Drive more efficient intake.
- Incident management SOP
Module 2: Incident response
The Purpose
- Clarify incident management steps, roles, and responsibilities.
Key Benefits Achieved
- Incident Management SOP and Workflows documented to drive consistent and effective incident response.
Activities
Outputs
Incident management workflow.
Critical incident management workflow.
Define SLOs and escalation rules.
- Incident management SOP (cont.)
- Incident management workflows
Module 3: Shift-left and problem management
The Purpose
- Outline a standard process for resolving problems.
Key Benefits Achieved
- Efficient and effective problem management, reducing incident recurrence and impact.
Activities
Outputs
Build KB process and KB article templates.
Identify additional shift-left opportunities (introduction).
Define problem management.
Standardize problem intake.
Standardize problem workflows.
- Knowledge management workflow
- Knowledge base article templates
- Problem management SOP
- Problem management workflow
Module 4: Proactive problem management and roadmap
The Purpose
- Plan how you will implement improvements.
Key Benefits Achieved
- Translate ideas into action, with specific steps to implement tangible improvements in the areas of people (training), process, and technology.
Activities
Outputs
Establish appropriate problem management governance.
Create a plan to communicate process changes.
Create a project roadmap to implement improvements.
Review workshop results.
- Communication initiatives list (to educate stakeholders on process changes)
- Roadmap to close gaps (for incident and problem management)
- Workshop results summary
Improve Incident and Problem Management
Rise above firefighter mode with structured incident management to enable effective problem management
EXECUTIVE BRIEF
Analyst Perspective
Keep it simple. Good data and consistent processes will help you break out of firefighter mode.
Incident management teams often find themselves too busy to create the knowledgebase (KB) articles or track the incident data that will save them time in the future. It becomes a vicious cycle that keeps them constantly in firefighter mode.
The key to breaking this cycle is to keep it simple as you seek to implement better structure and processes and right-size your approach. For example, avoid complex categorization schemes, and start with KB articles for known recurring incidents. Don’t jump to automation before you have the processes and resources to support it.
Similarly, when it comes to problem management, keep it simple by starting with Sev 1 tickets and recurring incidents that are obvious candidates for problem management. Support problem management with a consistent, structured approach that enables you to prioritize your limited resources.
As you build momentum with quick wins and better structure, improved incident management will drive more effective problem management and reduce future incidents as the incident-problem lifecycle comes full circle.
Frank Trovato
Research Director, Infrastructure and Operations
Info-Tech Research Group
Executive Summary
Your Challenge
Establish a consistent incident management process to better categorize, prioritize, and resolve incidents.
Enable faster resolution time through well-defined escalation protocols.
Prevent incidents from happening in the first place by identifying and resolving the underlying root cause via problem management.
Leverage event management to predict problems before potential incidents occur.
Common Obstacles
IT managers have conflicting accountabilities. It can be difficult to set aside time for preventing incidents (i.e., problem management) when staff are already busy resolving existing incidents and working on projects.
Resolving incidents quickly boosts confidence in IT, but recurring incidents erodes confidence, as does the need to use cumbersome workarounds.
Info-Tech’s Approach
Implement structured incident management to drive efficiency (e.g., effective use of categorization to drive appropriate ticket routing), and build out a knowledgebase to expedite future incident response.
On the problem management side, acknowledge that you have limited time for this, so start with obvious problems (e.g., recurring incidents) and then expand from there as problem management starts to reduce incident volume.
Info-Tech Insight
Effective problem management drives business value by preventing incidents, but it starts with good incident management that produces the data needed to identify problems that are driving recurring and related incidents. Specifically, logical categorization and resolution codes drive effective trend analysis to identify problems, and documenting troubleshooting, resolution details, and known errors provides a solid starting point for root cause analysis via problem management.
Common challenges to incident management success
Organizations that struggle with incident management (IM) are typically faced with these barriers:
Unresolved issues
- Tickets are not created for all incidents.
- Tickets are lost or escalated to the wrong technicians.
- Poor data impedes root-cause analysis of incidents.
Low productivity
- Lack of cross-training and knowledge sharing.
- Time is wasted troubleshooting recurring issues.
- Reports unavailable due to lack of data and poor categorization.
Poor planning
- Lack of data for effective trend analysis leads to poor demand planning.
- Lack of data leads to lost opportunities for templating and automation.
Expedite incident resolution with better data and focused documentation
| ITIL Incident Mgmt. Lifecycle | Key data and documentation to improve incident management |
|---|---|
| 1. Detection (identify, triage) | Improve ticket intake methods and triage to gather better data upfront (e.g., a web portal that can make required data mandatory). |
| 2. Registration (log ticket) | Capture as much detail as you can (e.g., context, affected system) to expedite troubleshooting, post-incident review, & problem management. |
| 3. Classification (categorize, prioritize) | Define a categorization scheme that drives appropriate ticket routing and identifying recurring incidents, but keep it simple — 3 layers max. |
| 4. Diagnosis (investigate) | Document known errors and KB articles for common incidents to increase first-call resolution and expedite troubleshooting. |
| 5. Resolution (solve, validate) | *Record solution details, update the category if necessary, and assign a resolution code to ensure more-accurate trends reporting. |
| 6. Closure (final updates) | Determine if a KB would expedite future troubleshooting or incident resolution. Don’t let lessons learned float away into the ether. |
*Category and resolution can also be updated at Closure if needed.
The Info-Tech difference:
- Start by analyzing your existing tickets. This translates theoretical goals and challenges into your reality.
- Identify specific issues that get in the way of better incident data and processes. Are there quick wins available?
- Define action items with a realistic time frame — short, medium, and long-term — to improve processes right-sized for your organization.
Leverage improved incident data to move from reactive to proactive mode with improved problem management
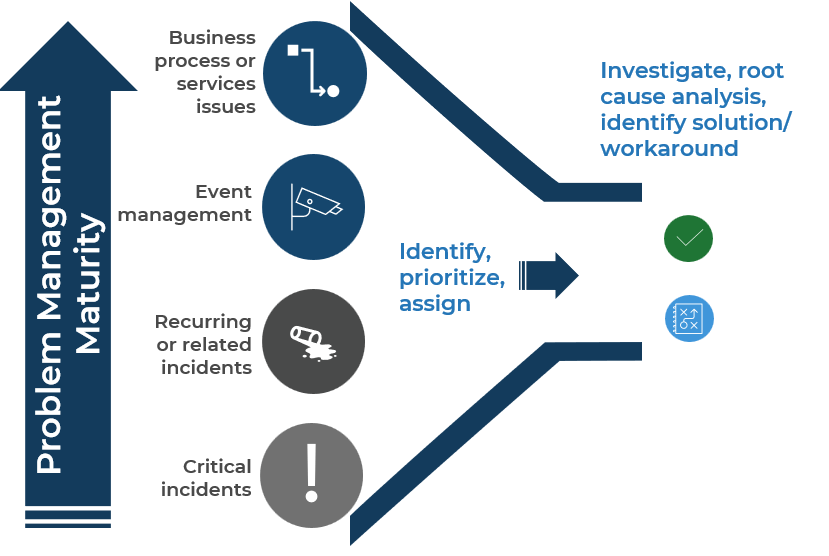
The Info-Tech difference:
- Problem management is a planned activity but with limited resources, so prioritizing your efforts is crucial.
- Start with known issues – critical incidents and recurring incidents identified through effective incident classification. This drives tangible business benefits that justify time spent on problem management.
- Not every problem has a viable or practical permanent resolution. A workaround that expedites resolving future occurrences of the incident can make more business sense, depending on the time and money needed for a permanent resolution.
STOP: Ensure you have foundational Service Desk operations before continuing
This blueprint will help you improve existing incident management processes, and then build on that foundation to implement or improve problem management.
If you need more foundational improvements to your Service Desk operations, we recommend starting with the blueprint Standardize the Service Desk.
Specifically, the following are pre-requisites for this blueprint:
- There is a formal process for submitting tickets or reporting issues (e.g., Service Desk email address, phone number, or portal).
- Ticket intake process separates incidents from service requests.
- Tier 1 roles are defined that manage ticket intake and provide first-call resolutions for low-complexity issues (e.g., forgot my password).
Info-Tech’s methodology to improve incident and problem management
| 1. Optimize Ticket Intake and Routing | 2. Standardize and Streamline Incident Response | 3. Establish Effective Problem Management | 4. Implement Improvements | |
|---|---|---|---|---|
| Phase Steps |
|
|
|
|
| Phase Deliverables |
|
|
|
|
Insight summary
Shift-left starts with a good knowledge base
A good knowledge base expedites incident resolution and supports “shift-left” (e.g., enabling Tier 1 to solve incidents that would otherwise escalate to Tier 2 or 3).
Every incident is potentially an opportunity to document a solution, troubleshoot steps, or establish relevant operational documentation needed solve the incident.
If you capture this information only in the ticket or your own personal repository, you limit the ability to shift left and expedite future incident resolution.
Don’t reinvent your processes because of a critical incident
All hands on deck doesn’t mean abandoning processes. Instead, supplement your existing incident management processes to maintain structure to your response. For example:
- Alert senior IT leads in case they’re needed but follow existing processes to triage and assign the incident to the right SMEs.
- Notify affected users as usual but add appropriate updates to senior leadership.
- Leverage existing incident response collaboration methods – e.g., use the same MS Teams channel you normally use to collaborate on incidents; if necessary, set up a separate channel for leadership updates.
Apply structure to problem management to find value
Time must be allocated to problem management to get the long-term benefits. It’s not going to be driven by the urgency of an outage, but rather the foresight to predict and prevent future incidents.
Effective problem management follows a structured process to get the most out of the time allocated to this proactive effort. This includes appropriate prioritization, a root cause analysis methodology, and a decision point on whether to adopt a workaround or continue to pursue a permanent solution.
If problem management is ad-hoc or “when I have time,” something else will always take precedence.
Blueprint deliverables
Each step of this blueprint is accompanied by supporting deliverables to help you accomplish your goals:
Incident Knowledgebase Article Examples
Use the examples as a guide for your KB article templates.
Incident, Critical Incident, and Problem Workflows
Workflows are critical to communication process expectations and driving consistent execution.
Incident Status Updates and Incident Report Templates
Modify our examples to suit your requirements.
Incident and Problem Management Project Roadmap
Identify, prioritize, and present initiatives to improve incident and problem management.
Key deliverable:
SOPs for Incident Management and Problem Management
Clarify process and role expectations to improve consistency, efficiency, and effectiveness.
Blueprint benefits
IT Benefits
- Documented incident management processes clarify expectations for Tier 1, 2, and 3 roles and drive consistent process execution.
- Capturing good incident data makes it easier to identify and resolve problems.
- Similarly, promoting knowledgebase development as part of your core process (e.g., identifying KB opportunities as part of resolving a ticket) not only expedites future incident resolution but also provides input to problem management to resolve the underlying root cause.
Business Benefits
- Quicker incident resolution through better process (e.g., routing tickets to the correct SMEs) and leveraging KB articles.
- Preventing recurring incidents by resolving the root cause.
- Predicting and preventing future incidents through proactive problem management.
Info-Tech offers various levels of support to best suit your needs
DIY Toolkit
“Our team has already made this critical project a priority, and we have the time and capability, but some guidance along the way would be helpful.”
Guided Implementation
“Our team knows that we need to fix a process, but we need assistance to determine where to focus. Some check-ins along the way would help keep us on track.”
Workshop
“We need to hit the ground running and get this project kicked off immediately. Our team has the ability to take this over once we get a framework and strategy in place.”
Consulting
“Our team does not have the time or the knowledge to take this project on. We need assistance through the entirety of this project.”
Diagnostics and consistent frameworks used throughout all four options
Guided Implementation
What does a typical GI on this topic look like?
A Guided Implementation (GI) is a series
of calls with an Info-Tech analyst to help implement our best practices in your organization.
A typical GI is between eight and 12 calls over the course of four to six months.
| Phase 1 | Phase 2 | Phase 3 | Phase 4 |
|---|---|---|---|
| Call #1: Scope requirements, objectives, and your specific challenges. | Call #3: Incident Management Workflows. | Call #6: Problem ticket sources. | Call #9: Plan how you will communicate changes. |
| Call #2: Incident ticket intake and routing. | Call #4: Critical Incident Workflows. | Call #7: Problem management workflows. | Call #10: Create a project roadmap to implement improvements. |
| Call #5: Complete the Incident Management SOP | Call #8: Complete the Problem Management SOP |
Phase 1: Optimize Ticket Intake and Routing
Phase 1
Optimize Ticket Intake and Routing
Phase 2
Standardize and Streamline Incident Response
Phase 3
Establish Effective Problem Management
Phase 4
Implement Improvements
This phase will walk you through the following steps:
- Review the incident lifecycle and your current challenges.
- Improve how you identify, log, and categorize incidents.
- Define a ticket prioritization scheme.
- Drive more efficient ticket intake.
Improve Incident and Problem Management
Step 1.1
Review the incident lifecycle and your current challenges
Activities
1.1.1 Identify challenges with your existing incident management processes
This step will guide you through the following content and activities:
- Establish a common understanding of the incident lifecycle.
- Identify challenges with your existing incident management processes.
This step involves the following participants:
- Incident Management Team (e.g., Tier 1 and 2 roles and the Incident Manager)
- Tier 3 reps from relevant IT teams (e.g., network, servers, security, apps, etc.)
Outcomes of this step
- Level-setting across the team regarding incident lifecycle stages, based on ITIL.
- High-level challenges identified with your existing incident management processes.
Blueprint pre-step: Gather your data to relate this blueprint to your reality
Before you begin this project, gather the data from your existing ticketing system.
You will use this data as you work through this blueprint to help you make decisions on what the target state of your incident management program looks like.
You will need:
- An export of your existing ticket categorization scheme; raw data is better so you can easily manipulate the data as you are analyzing it.
- Each person on the project team will pull ten tickets from each priority level you are currently using (10 sev1, 10 sev2, 10 sev3).
- A snapshot of the incident ticket interface to be able to quickly reference existing fields and functionality.
This image will help remind you to search through your own ticket data to help guide your decisions during the design phase of incident management.
Establish a common understanding of the incident lifecycle
1) Detection: User reporting an issue, event triggering an alert, and so on. Conduct initial triage/discovery. Confirm it’s an incident (for service requests, follow a separate process).
2) Registration: Create/update the ticket based on initial triage (e.g., incident details) or monitoring system that generated the alert (e.g., relevant system).
3) Classification: Categorize, prioritize, and conduct initial investigation (e.g., check KB for known errors). Escalate or re-assign if necessary.
4) Diagnosis: Additional investigation if solution not already identified. Peer discussion, check KB, and/or consult vendor. Escalate or re-assign if necessary.
5) Resolution: Apply solution (permanent fix or workaround) to restore service. If applicable, submit a change request to move the fix into production.
6) Closure: Finalize ticket details, including status (Closed). Provide final update to affected users. Identify if a KB is needed to expedite future troubleshooting or incident resolution.
Note: Ideally, steps 1 to 3 are executed by Tier 1 staff so that Tier 2 and 3 are included only when an issue needs to be escalated. This drives lower-cost resolution and frees time for Tier 2 and 3 to focus on project work, more-complex incidents, and problem management. Ticket updates occur throughout and are finalized as needed at Closure.
1.1.1 Identify challenges with your existing incident management processes
1-3 hours
Materials
- Whiteboard or flip chart
Participants
- Incident Management Team (e.g., Tier 1 and 2 roles and the Incident Manager)
- Tier 3 reps from relevant IT teams (e.g., network, servers, security, apps, etc.)
- As a group, outline the challenges or weaknesses you have in each step of the incident lifecycle. Separate the challenges into people, process, and technology for a wholistic view.
- Record those challenges for reference purposes. Phase 4 will include creating a project roadmap to address gaps and improve processes.
- Below are examples of common challenges to consider:
- Are incidents resolved at the appropriate Tier? Are Tier 2 and 3 resolving incidents that could be solved at a lower Tier?
- Any challenges with identifying ticket type, category, or severity level? Is it clear where to route tickets (e.g., based on category)?
- Is it clear when to escalate tickets? Is Tier 1 gathering enough information before escalating?
- Is ticket data updated appropriately by Tier 2 or 3 staff?
- Is there appropriate documentation available to support ticket troubleshooting (e.g., system information, relevant KB articles, etc.)?
- Any common complaints from users or executives (e.g., slow response, ticket status is unclear)?
- Below are examples of common challenges to consider:
Step 1.2
Improve how you identify, log, and categorize incidents
Activities
1.2.1 Review and update your categorization scheme
1.2.2 Define resolution codes to further improve reporting
This step will guide you through the following content and activities:
- Separate incidents from service requests
- Understand categorization best practices
- Review/update categorization scheme
- Define resolution codes to further improve reporting
This step involves the following participants:
- Incident Management Team (e.g., Tier 1 and 2 roles and the Incident Manager)
- Tier 3 reps from relevant IT teams (e.g., network, servers, security, apps, etc.)
Outcomes of this step
- Improved ticket categorization scheme and resolution codes.
- Knowledge sharing between teams regarding proper use of categories and resolution codes.
About Info-Tech
Info-Tech Research Group is the world’s fastest-growing information technology research and advisory company, proudly serving over 30,000 IT professionals.
We produce unbiased and highly relevant research to help CIOs and IT leaders make strategic, timely, and well-informed decisions. We partner closely with IT teams to provide everything they need, from actionable tools to analyst guidance, ensuring they deliver measurable results for their organizations.
What Is a Blueprint?
A blueprint is designed to be a roadmap, containing a methodology and the tools and templates you need to solve your IT problems.
Each blueprint can be accompanied by a Guided Implementation that provides you access to our world-class analysts to help you get through the project.
Need Extra Help?
Speak With An Analyst
Get the help you need in this 7-phase advisory process. You'll receive multiple touchpoints with our researchers, all included in your membership.
Guided Implementation 1: Identify and manage major/critical incidents
- Call 1: Outline the potential benefits of a critical incident management procedure.
- Call 2: Review the results of the voting exercise and the list of exceptions.
Guided Implementation 2: Develop problem management procedures
- Call 1: Outline the benefits of a problem management regimen and the required resources.
- Call 2: Review the separated lists of incidents and problems.
- Call 3: Review the incident matching procedure.
Guided Implementation 3: Engage in proactive problem management
- Call 1: Outline the required inputs for proactive problem management.
- Call 2: Review proactive problem management techniques.
- Call 3: Collate and present the visual SOPs.
Guided Implementation 4: Optimize ticket intake and routing
- Call 1: Scope requirements, objectives, and your specific challenges.
- Call 2: Incident ticket intake and routing.
Guided Implementation 5: Standardize and streamline incident response
- Call 1: Incident Management Workflows.
- Call 2: Critical Incident Workflows.
- Call 3: Complete the Incident Management SOP.
Guided Implementation 6: Establish effective problem management
- Call 1: Problem ticket sources.
- Call 2: Problem management workflows.
- Call 3: Complete the Problem Management SOP.
Guided Implementation 7: Implement improvements
- Call 1: Plan how you will communicate changes.
- Call 2: Create a project roadmap to implement improvements.
Contributors
- Hardy Baker, Incident and Problem Manager, Waste Management
- Rishi Bhargava, Co-Founder Demisto Inc.
- Rob England, Managing Director, Two Hills Ltd.
- Steven Ingram, Data Engineer, Wave HQ
- George Jucan, Founder, Organizational Performance Enablers Network
- Rick Moroz, Associate Director, Information Systems, University of Guelph
 Create a Service Management and IT Operations Strategy
Create a Service Management and IT Operations Strategy
 Optimize the IT Operations Center
Optimize the IT Operations Center
 Improve Incident and Problem Management
Improve Incident and Problem Management
 Optimize IT Change Management
Optimize IT Change Management
 Harness Configuration Management Superpowers
Harness Configuration Management Superpowers
 Develop Infrastructure & Operations Policies and Procedures
Develop Infrastructure & Operations Policies and Procedures
 Stabilize Release and Deployment Management
Stabilize Release and Deployment Management
 Deploy AIOps to Improve IT Operations
Deploy AIOps to Improve IT Operations
 Improve IT-Business Alignment Through an Internal SLA
Improve IT-Business Alignment Through an Internal SLA
 Implement Infrastructure Shared Services
Implement Infrastructure Shared Services
 Next-Generation InfraOps
Next-Generation InfraOps
 Reduce Manual Repetitive Work With IT Automation
Reduce Manual Repetitive Work With IT Automation
 Take Control of Cloud Costs on AWS
Take Control of Cloud Costs on AWS
 Take Control of Cloud Costs on Microsoft Azure
Take Control of Cloud Costs on Microsoft Azure
 Govern Shared Services
Govern Shared Services
 Take Control of Infrastructure and Operations Metrics
Take Control of Infrastructure and Operations Metrics
 Engineer Your Event Management Process
Engineer Your Event Management Process
 Design Your Cloud Operations
Design Your Cloud Operations
 Build a Continual Improvement Program
Build a Continual Improvement Program
 Align Projects With the IT Change Lifecycle
Align Projects With the IT Change Lifecycle
 Drive Business Value With Microsoft 365 Copilot
Drive Business Value With Microsoft 365 Copilot
 Build Seamless IT Operations With Automation
Build Seamless IT Operations With Automation
 Transition and Operationalize Incoming Projects
Transition and Operationalize Incoming Projects
 Cut Costs by Leveraging AI Solutions
Cut Costs by Leveraging AI Solutions
 Harness AI to Reduce the Cost and Effort of KTLO in IT Operations
Harness AI to Reduce the Cost and Effort of KTLO in IT Operations
 AI in Seven Charts
AI in Seven Charts
 Emerging AI Trends and Predictions From Our Global Technical Counselor Team
Emerging AI Trends and Predictions From Our Global Technical Counselor Team
 People Change in the Face of Disruptive Technology
People Change in the Face of Disruptive Technology
 Lead IT Like a Business: Every Dollar Is a Decision
Lead IT Like a Business: Every Dollar Is a Decision
 Optimize Cloud & AI Spend With Agentic FinOps
Optimize Cloud & AI Spend With Agentic FinOps
 Beyond Firefighting: Tactics to Elevate Your Role in Infrastructure & Operations
Beyond Firefighting: Tactics to Elevate Your Role in Infrastructure & Operations
 Influence Unleashed: The IT Leader’s Superpower
Influence Unleashed: The IT Leader’s Superpower
 The Challenge of Ethics in the Use of AI
The Challenge of Ethics in the Use of AI
 Introducing the Info-Tech Speakers Bureau
Introducing the Info-Tech Speakers Bureau
 Inside the Agentic Enterprise
Inside the Agentic Enterprise
 Agents 2.0: From Autonomy to Architecture
Agents 2.0: From Autonomy to Architecture
 Agentic IT: From Hype to Value
Agentic IT: From Hype to Value
 Tech Trends 2027 Keynote
Tech Trends 2027 Keynote
 Become an Exponential CIO
Become an Exponential CIO
 Beyond the Agent: The Leadership Ecosystem for an AI-Enabled World
Beyond the Agent: The Leadership Ecosystem for an AI-Enabled World
 Five Key Takeaways From Info-Tech LIVE 2026
Five Key Takeaways From Info-Tech LIVE 2026