NVIDIA's GTC 2026: A Platform Bid Disguised as a Hardware Launch
What technology leaders need to understand what NVIDIA's new products mean for their budgets, their vendors, and their risk exposure.
At GTC 2026, NVIDIA founder and chief executive Jensen Huang argued that companies are no longer buying compute. They are building token factories, deploying AI agents as workers, and competing on how efficiently they turn power into business output. Technology leaders need to understand what this shift means for their budgets, their vendors, and their risk exposure.
Image source: Shashi Bellamkonda
What NVIDIA Announced at GTC 2026 (March 2026)
Note: Some capabilities are available now. Others are on the roadmap for later in 2026.
1. A New Way to Think About AI Spending: The Token Factory
In the current environment, AI tokens are regarded as operational costs. Providers often set prices for tokens – units of output produced by AI systems – when responding to inquiries, generating code, or making decisions.
In his keynote, Jensen Huang took the position that data centers are now factories. The raw material is power. The product is tokens.
NVIDIA's framing gives finance teams a manufacturing metric to evaluate AI investments: cost per token, revenue per megawatt. This replaces abstract computing benchmarks with something that looks like a production efficiency model.
The advantage is creating a shared language for making AI investment choices. Rather than arguing over which graphics processing units (GPU) setup to purchase, business and IT leaders can focus on outcome-based metrics that link infrastructure costs directly to business outcomes. This approach simplifies building a budget proposal and reduces the likelihood of AI initiatives being dismissed as mere technical experiments.
Why this matters to you: If your CFO or board starts asking about token throughput or cost per AI output, NVIDIA shaped that conversation before it reached your desk.
2. From AI Factories to Sovereign Infrastructure: Optimizing the Five-Layer Stack
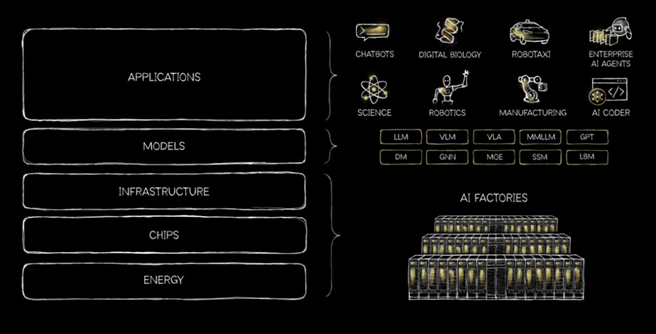
Image Source: Shashi Bellamkonda
Jensen Huang framed AI not as a single technology but as a “a five-layer cake,” spanning energy, chips and computing infrastructure, cloud data centers, AI models, and ultimately, the application layer. The essential infrastructure for AI production is the “AI factory,” where data comes in and intelligence comes out. These are next-generation data centers that host advanced, full-stack, accelerated computing platforms for the most computationally intensive tasks.
Nations are building up domestic computing capacity through various models. Some are procuring and operating sovereign AI clouds in collaboration with state-owned telecommunications providers or utilities. Others are sponsoring local cloud partners to provide a shared AI computing platform for public- and private-sector use.
The transition to sovereign AI requires a fundamental shift in infrastructure. As Jensen Huang, founder and CEO of NVIDIA, states, “The AI factory will become the bedrock of modern economies across the world.” The Economist argues that China’s expanding, low-cost power grid gives it a potential edge in AI, but a lack of advanced chips and poor data center planning limit its ability to leverage this advantage. Some believe that owning infrastructure will be the key factor in leading the AI economy.
Why this matters to you: This is important if you are seeking direction on how to optimize the layers of the AI technology stack. To optimize the deployment and usage of AI technologies for an organization or a country, this will require a solid AI strategy and an AI governance plan (some will also require guidance in building an AI sovereignty strategy).
3. AI Agents as the New Enterprise Workforce: The OpenClaw Risk You May Already Have
NVIDIA introduced OpenClaw as an open-source platform for running AI agents continuously on devices and inside company networks. Unlike a chatbot that responds when asked, these agents work independently, remember context across sessions, and can take action in connected systems without a human approving each step. NVIDIA positioned this as the next productivity layer, with agents handling tasks that currently require human attention.
A frequently overlooked aspect of the product announcement concerns OpenClaw’s open-source nature. This enables employees to access the tool without awaiting a formal IT deployment.
In practice, orchestrating tools across platforms without appropriate IT support is typically more complex than vendors may indicate, especially since many organizations implement strict controls on work devices. Security teams are advised to regard such activity as currently occurring within their environment, rather than considering it a potential future development.
NemoClaw is NVIDIA's open-source governance framework, released specifically to help enterprises manage this risk. It is designed to give IT teams control over what agents can access, what actions they can take, and what gets recorded in an audit trail. OpenShell adds policy enforcement and network-level controls on top of that foundation. NVIDIA released these tools in recognition that the agent deployment risk is real and immediate, not theoretical.
The benefit – when properly governed, agents can be created by individual employees to handle repetitive, time-sensitive work across systems continuously, increasing output without proportional headcount growth. The governance tools exist to make that expansion manageable rather than a liability. But the benefit only materializes if the governance is in place before the agents are running on a scale, not after an incident.
Why this matters to you: Your employees are likely already using OpenClaw or similar agent tools on work devices. Shadow agents? The question is not whether to allow agents. It is whether you have governance in place before they cause a problem. Evaluate NemoClaw as your starting point for enterprise agent controls. Treat it as a security deployment, with the same rigor you would apply to any privileged access tool.
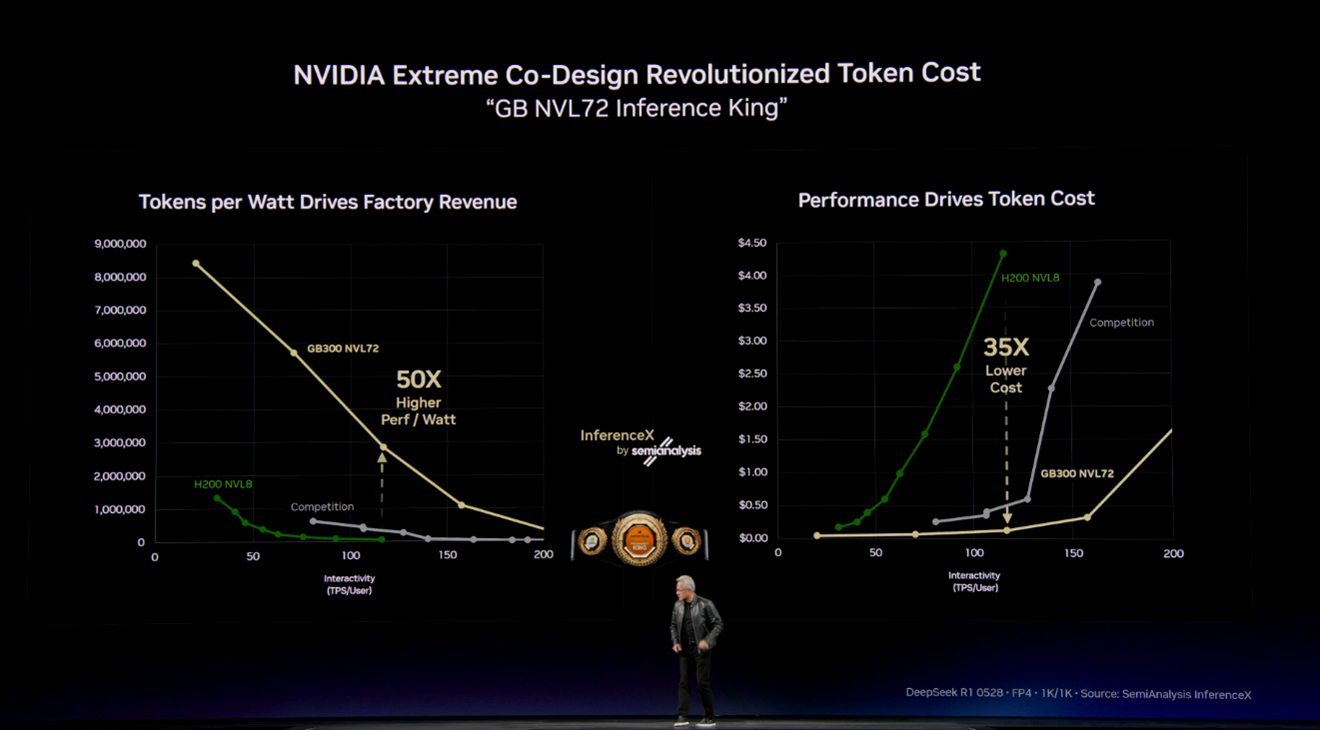
Image Source: Shashi Bellamkonda
4. Vera Rubin: The Next Hardware Generation and Falling AI Costs
Huang outlined the new Vera Rubin hardware platform, which combines next-generation GPUs, central processing units (CPUs), and networking into tightly integrated rack-scale systems. He is very passionate about showing off NVIDIA’s hardware at GTC events. There is a good branding goal to this, as for decades everyone has seen NVIDIA stickers on laptops (graphic cards). The brand is visible, and that visibility continues.
NVIDIA claims significant improvements in processing speed and cost per output compared to the current generation. These systems are designed primarily for large-scale AI inference, meaning running AI models in production rather than training them.
One of the more significant signals from GTC 2026 is what this trajectory means for pricing. Each generation of NVIDIA hardware has driven down the cost of AI output substantially.
The practical effect is that AI workloads that are expensive to run today will become significantly cheaper within 12 to 24 months, as these systems reach cloud providers and the competitive pressure from AMD, Broadcom, and others intensifies. Organizations that delay AI deployment citing cost concerns may find those concerns resolve themselves through market forces.
Why this matters to you: If cost has been a barrier to expanding AI in your organization, build your roadmap with falling unit costs as an assumption, not a hope. Most of your AI workloads will be cheaper to run in 2027 than they are today. Do not let current pricing set the ceiling on your ambition.
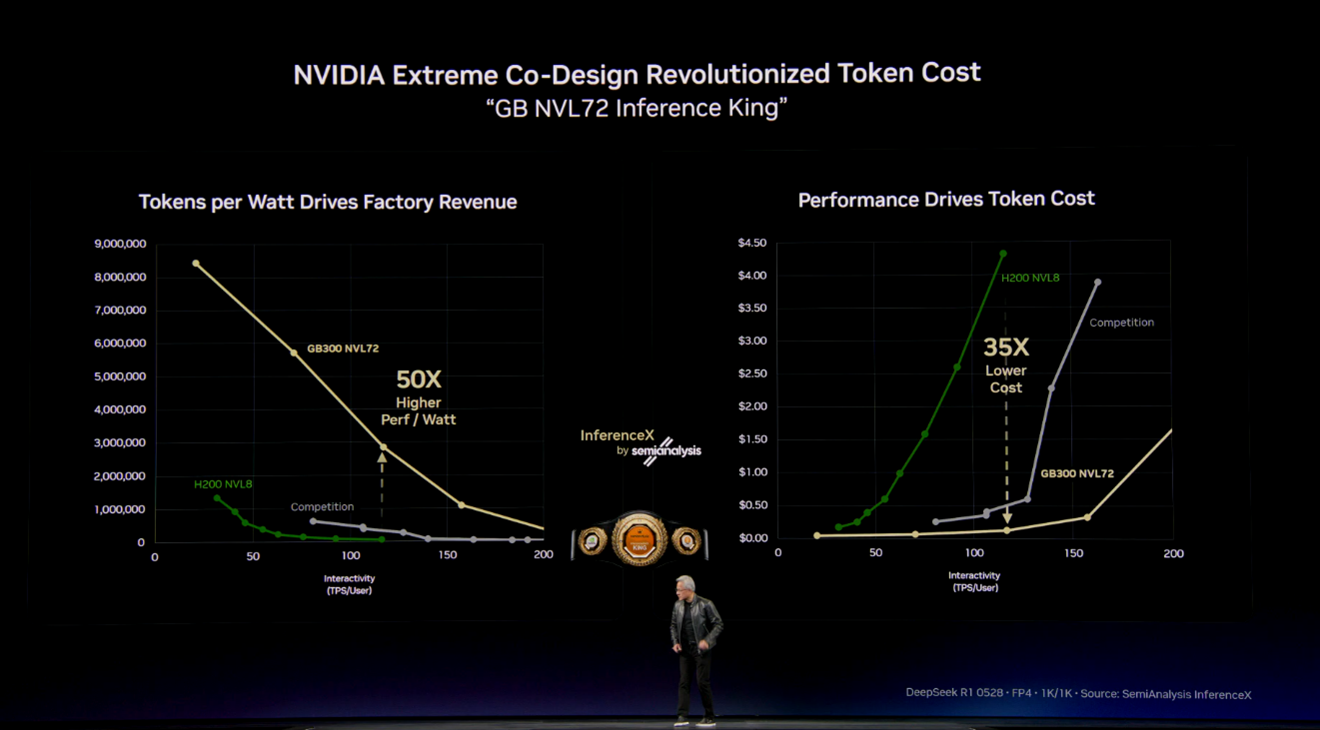
Image Source: Shashi Bellamkonda
5. Dynamo and DSX: Managing the Infrastructure Behind AI
NVIDIA's Dynamo is a software layer managing AI workloads across various infrastructures, while DSX offers tools for designing and operating large-scale AI facilities, including power and capacity planning. Both are essential for organizations running AI at scale, allowing advanced management of resources that traditional data center tools cannot handle. Dynamo and DSX simplify operations and remove the need for custom engineering solutions.
Why this matters to you: Adopting Dynamo or DSX as a standard means accepting NVIDIA's model for how AI infrastructure is managed. These are architectural decisions, not software subscriptions. Make them deliberately, with a clear view of what you would need to replace if you ever wanted to change direction.
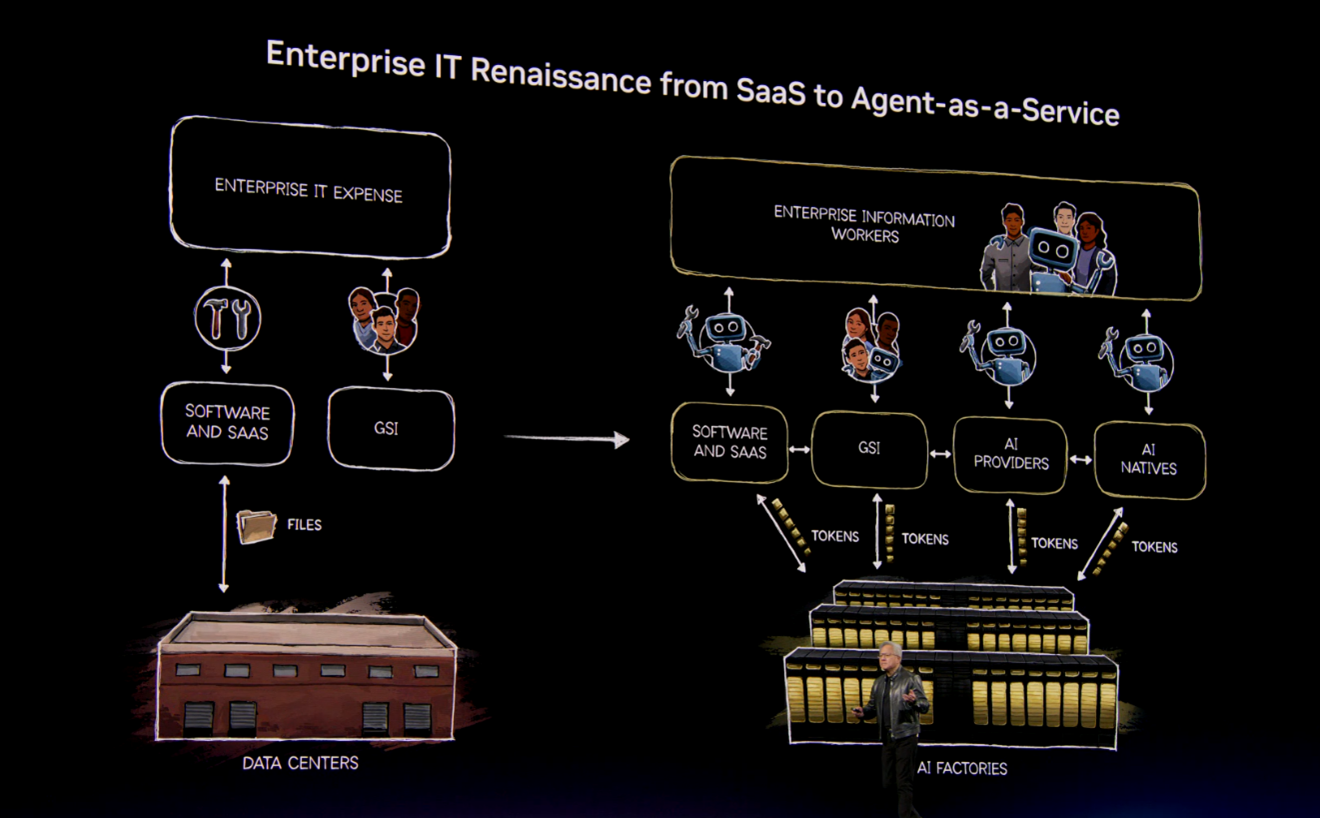
Image Source: Shashi Bellamkonda
6. Open Models and the Nemotron Coalition
NVIDIA announced broader support for its open model families, such as Nemotron for language tasks and specialized variants for industries like healthcare and robotics, in partnership with various collaborators. This move reflects a commitment to open development alongside proprietary offerings. Open models provide flexible, cost-effective AI solutions, allowing teams to customize and deploy models without relying entirely on closed commercial platforms or facing unexpected pricing or access issues.
Why this matters to you: Scrutinize the open-source commitments carefully. Ask which parts are genuinely open, what the license terms allow your organization to do, and whether a future version of NVIDIA's roadmap could restrict access your teams are building on today.
7. You Will Access NVIDIA's Technology Through Your Cloud Provider, Not Directly
Most enterprise tech leaders don't buy NVIDIA hardware directly; instead, cloud providers operate it and offer AI services powered by NVIDIA. Major providers like AWS, Azure, Google Cloud, IBM Cloud, and Oracle run large-scale NVIDIA infrastructure, while others like Vultr and Lambda Labs provide more direct and cost-effective access. As a result, GTC 2026 innovations – such as Vera Rubin performance boosts and lower costs – will appear in your cloud provider's AI services, not as separate features but through better performance and new capabilities. This setup lets organizations access advanced AI without managing hardware, while smaller providers give more control and potentially lower costs for those who prefer hands-on model management.
Why this matters to you: Review your AI workloads against what your current cloud providers are offering on NVIDIA infrastructure. If you are running significant inference workloads, compare hyperscaler pricing against specialist GPU cloud providers. The cost differences can be substantial. For organizations already committed to AWS, Azure, or Google Cloud, GTC announcements will flow through as service improvements over the next 12 to 18 months. You do not need to react to the hardware announcement directly.
Our Take
NVIDIA is attempting to become the default platform for enterprise AI, the way Microsoft became the default platform for productivity. GTC 2026 was the clearest public statement of that ambition. Most technology leaders will never interact with NVIDIA directly. They will feel this through their cloud providers, their software vendors, and their employees’ laptops.
The agent story is the one that requires immediate attention. OpenClaw is open source. Employees are using it. The question of whether your organization allows autonomous AI agents is already being answered on the ground, without a policy in place.
NemoClaw is NVIDIA's answer to that problem, and it is worth evaluating now, not after an incident. Treat it as a security deployment: test the controls, verify the audit trail, and define what agents are and are not permitted to access before the scope of the problem grows.
IT teams will have a strong knee-jerk reaction against shadow agents, same way they pushed back hard on shadow apps
On cost: the trajectory is favorable. AI output costs are falling with each hardware generation, and competition among cloud providers and GPU specialists is accelerating that trend. Organizations that have delayed AI investment citing cost barriers should be reassessed. The business case that does not work today at current prices may look very different in 18 months.
The strategic decision that remains is how much of your AI architecture you want to standardize on a single vendor's model, even indirectly through a cloud provider. The value of integration and simplicity is real. So is the cost of changing direction later. Make that decision deliberately, document it, and revisit it annually as the market continues to move.